Token? Context Window? RAG? 一次看懂 AI 專有名詞
前幾個月開始在一間 AI 新創公司打工,接觸到了一堆有的沒的專有名詞,像是 Token、 Context Window、 RAG、 Embedding、 Vector Database 這些對一個剛接觸 LLM 的小白很陌生的生詞。 最近似乎打通了任督二脈,有比較理解這些概念的傾向。決定寫一篇文來和大家分享一下我的理解。
不知道大家有沒有在和 GPT 或其他 LLM 聊天的時候發現,有的時候 LLM 的回答會突然在奇怪的地方中斷?就和那些做短影片只做前半段吸引你的內容但不給後面結尾的優秀 Youtuber 一樣,玩弄你的好奇心。會發生這個情況的可能有兩種,第一種就是你的使用上限超過了,該課金了或是要等冷卻時間,第二種就是 AI 「忘記」該怎麼回答你的問題了。 什麼? LLM 這個萬能的願望機居然也會犯這種低級錯誤?
LLM 為什麼會「忘記」你問的的問題? 所有的 LLM 都有一個記憶上限。使用者輸入的問題加上 LLM 回覆的「字數」有一定的上限。用來測量字數多寡的單位就是 Token。而這個記憶的上限就是 Context Window。
一個英文單字大概是 1.3 個 Token,一個中文字大概是 1.5 個 Token。但同樣的一段文字對於不同 LLM 來說, Token 的數量有可能會不同。
二十個 GPT 的 Token 不等於二十個 Claude 的 Token。就像是 $10 元美金不等於 $10 元新台幣一樣。 所以如果你問 GPT 和 Claude 一模一樣的問題,且他們的回答也一模一樣,使用的 Token 數量也有可能會不同。
LLM 並無法知道你上個問題問了什麼,每一個問題都是一個新的開始。網頁版的 GPT 可以「記得」你前幾個問題,其實是用了一個小把戲。 那就是在你問最新的問題的時候,把之前的聊天歷史都一起餵給 LLM。當你和 LLM 的聊天歷史越來越長,每次餵給 LLM 的 Token 就越多,就越有可能會在下次回答超出 Context Window 的大小。超過 Context Window 的部分就會直接被腰斬。 為了解決這個問題,GPT 會在背後偷偷「忘記」你最早問的問題,這樣就能預留一點 Context Window 的空間給最新的回答。 當然還有一些其他的小把戲可以防止回答被腰斬,但是丟掉最早的歷史紀錄是最簡單的方法。
理解了 Context Window 的概念之後,就可以來聊聊 RAG 了。 RAG 是什麼? 抹布。地毯式搜索聽過吧? RAG 就是抹布式搜索 (喂。
大部分的 LLM 都支援檔案上傳,也有能力回答與檔案內容相關的問題。那假設你今天被吉,想要請教一下你的御用法律顧問 GPT 該如何應對。你可以試著暴力的把六法全書餵給 GPT,把你小時候被爸媽、老師、逼著唸書的怨氣都發在 GPT 身上。
我請我的特助 Dr. Deepseek 幫我估算一下,六法全書大概有 80 萬個字,也就是大約 120 萬個 Token。目前沒有任何一家的 LLM 能夠完全讀完六法全書,所以你讀得完你就超越 LLM 了。
以下是我的秘書 Dr. GPT 整理的常用 LLM Context Window Size
| Model | Context Window (Tokens) |
|---|---|
| GPT-4-turbo | 128K |
| GPT-4 | 8K |
| GPT-3.5-turbo | 16K |
| Claude 3 Opus | 200K |
| Claude 3 Sonnet | 200K |
| Claude 3 Haiku | 200K |
| Claude 2 | 100K |
| Gemini 1.5 Pro | 1M |
RAG 就是一個能讓 LLM 讀大量資料的方法。 以下是一個簡單的 RAG 流程。
首先六法全書會被拆成好幾個小段落,而每一個段落會被餵給一個 Embedding Algorithm。Embedding Algorithm 是什麼?我也不知道。我只知道他會把一段文字轉化成一個向量,容易出現在一起的文字向量會距離比較近。舉個例子:Kelvin 和 大帥哥 這兩個詞比較容易會一起出現,所以 Kelvin 和 大帥哥 的 Embedding (向量) 就會距離比較近,而醜八怪基本上和 Kelvin 扯不上關係,所以距離 Kelvin 就會很遠。 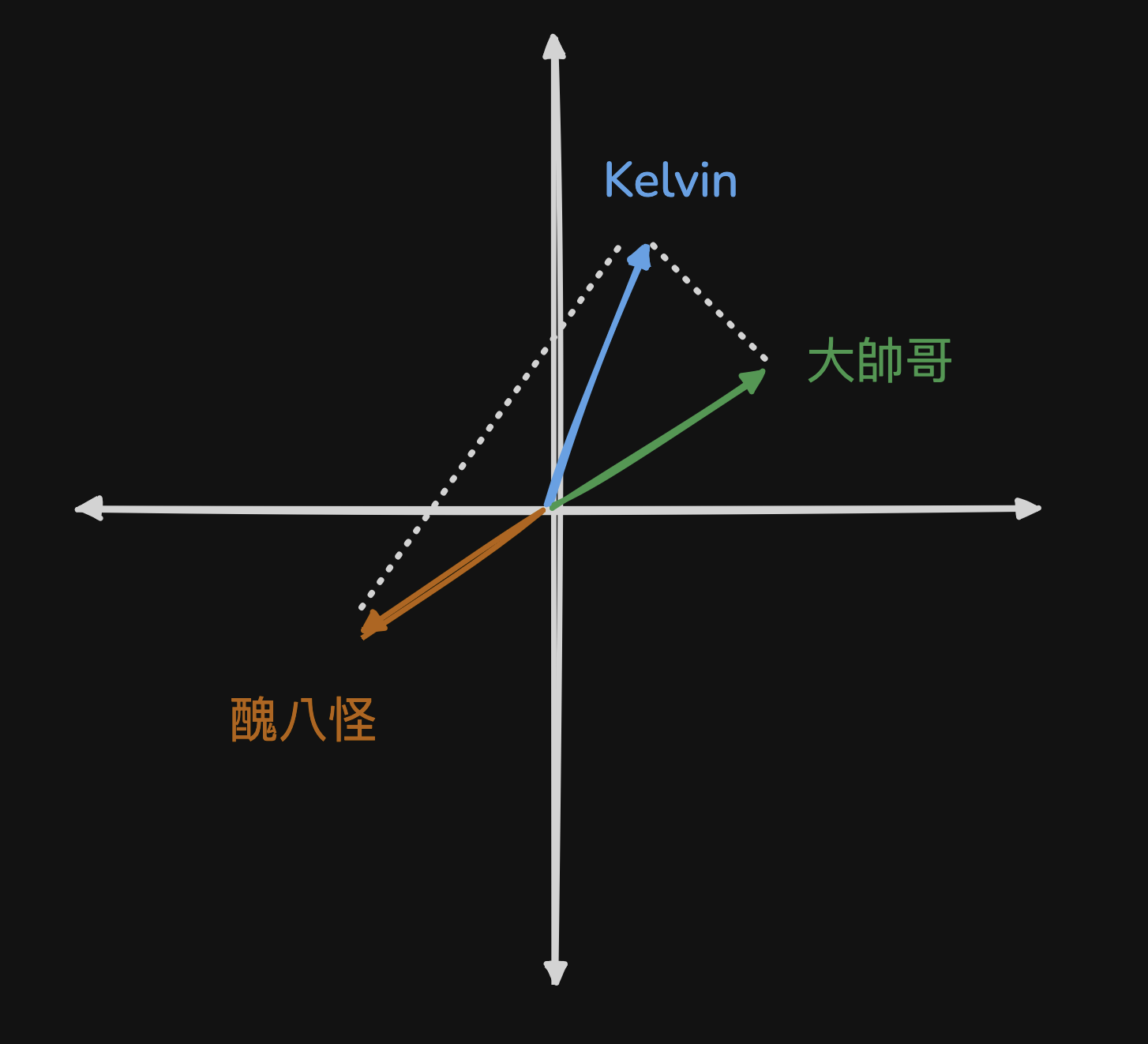
回到剛剛的例子,六法全書被拆成小片段之後,每一個片段都會被轉成 Embedding ,最後所有的內容都會被存在一個向量資料庫 (Vector Database)。
向量資料庫長這樣:
| 內容 | 向量 |
|---|---|
| 民法… | [0.1, 0.3, 0.5, …] |
| 刑法… | [0.4, 0.6, 0.8, …] |
六法全書全部都存在在資料庫之後,當使用者問一個和民法相關的問題時,使用者的問題會被餵入 Embedding Algorithm 並轉化成向量,而這個向量可以用來查找資料庫裡最相近的內容。如此一來就能夠精準的截取六法全書裡最有機會能夠回答使用者問題的部分。最後只要把這一小部分和使用者的問題一起餵入 LLM 就可以做出 LLM 好像是法學專家的假象囉!所以簡單來說 RAG 就是一個能讓 LLM 斷章取義的酷東西。當然抹布式搜索可以也可以做得非常厲害,變成地毯也不是沒有可能,這就看各位大神的功力囉。